Data Quality
Data Quality in Relation to Data Catalogues
A data catalogue is like an organised library for an organisations data assets.
It stores metadata (schema, ownership, lineage, classification, quality metrics, etc.), so users can discover, understand, and trust the data. Data quality in this context refers to the accuracy, completeness, consistency, timeliness, and validity of the data sets described in the catalogue.
A good catalogue doesn’t just list tables and columns, it should also surface quality indicators that tell users whether a dataset is reliable.
For example:
- Data profiling metrics: Null percentages, unique value counts, min/max values.
- Test results: Outcomes from automated checks (like DBT tests) verifying business rules.
- Freshness information: Last update times, latency vs. expected SLAs.
- Data lineage: Tracing where the data came from and transformations applied.
By integrating quality metrics into the catalogue, analysts can quickly answer:
“Is this dataset fit for my purpose?” “When was it last validated?” “Has it passed recent quality checks?
CaDet Property Data POC
In order to improve the quality of data in Datahub, we are working on a proof of concept to use DBT tests to validate data quality, for selected CaDeT assets.
This will allow us to define rules for data quality checks and automatically flag any issues.
CaDet (Create a derived table) is a repository of DBT related code that allows us to create derived tables and run tests on them.
What DBT Is and What It Does
DBT (short for Data Build Tool) is an open-source framework for transforming data inside a data warehouse using SQL and Jinja templating.
Instead of pulling data out of the warehouse and transforming it elsewhere, DBT works in-warehouse: You write transformation logic as SQL models.
DBT compiles those into SQL statements your query engine understands (BigQuery, Snowflake, Redshift, Athena). It runs them in the right order, manages dependencies, and materializes results as views or tables.
Key Things DBT Does:
- Modular SQL development
- Break transformations into small, reusable “models” instead of giant SQL scripts.
- Reference other models with ref() so DBT automatically builds a dependency graph.
- Version control + collaboration
- All transformations live in code, so you use Git for versioning and review.
- Makes data engineering feel more like software engineering.
- Testing and documentation
- Write data tests (null checks, uniqueness, business rules).
- Auto-generate documentation, including lineage diagrams.
- Environment management
- Easily run transformations in dev, staging, and prod environments.
Orchestration:
Can be run manually, on a schedule, or triggered by orchestration tools like Airflow or dbt Cloud.
Typical Workflow:
- Raw data lands in your warehouse (from ETL/ELT tools like Fivetran or Airbyte).
- DBT models clean, join, and shape it into analytics-ready tables.
- Tests validate the transformed data.
- Docs and lineage help users understand where the data came from and whether it’s trustworthy.
In short:
DBT turns raw data into clean, tested, documented datasets ready for analytics — all using SQL, version control, and modern software engineering practices.
Approach
For the POC we decided to implement three main tests:
Column Completeness
Measures whether all expected values in a column are present (i.e. not NULL). A high completeness score means the dataset has few or no missing values in that column.
Why it matters:
Missing values can break business logic, skew analysis, or cause downstream errors.
Column Consistency
Ensures that values in a column follow the expected format, range, or pattern. This guards against incorrect data entry or upstream pipeline errors.
Why it matters:
Inconsistent data (e.g., mixed date formats, invalid codes) leads to unreliable analytics and incorrect joins.
Column Uniqueness
Checks that each value in a column appears only once (no duplicates). Often used for identifiers like primary keys or business keys.
Why it matters:
Duplicates in supposed unique identifiers can cause double counting, incorrect joins, and reporting errors.
Property DBT Models
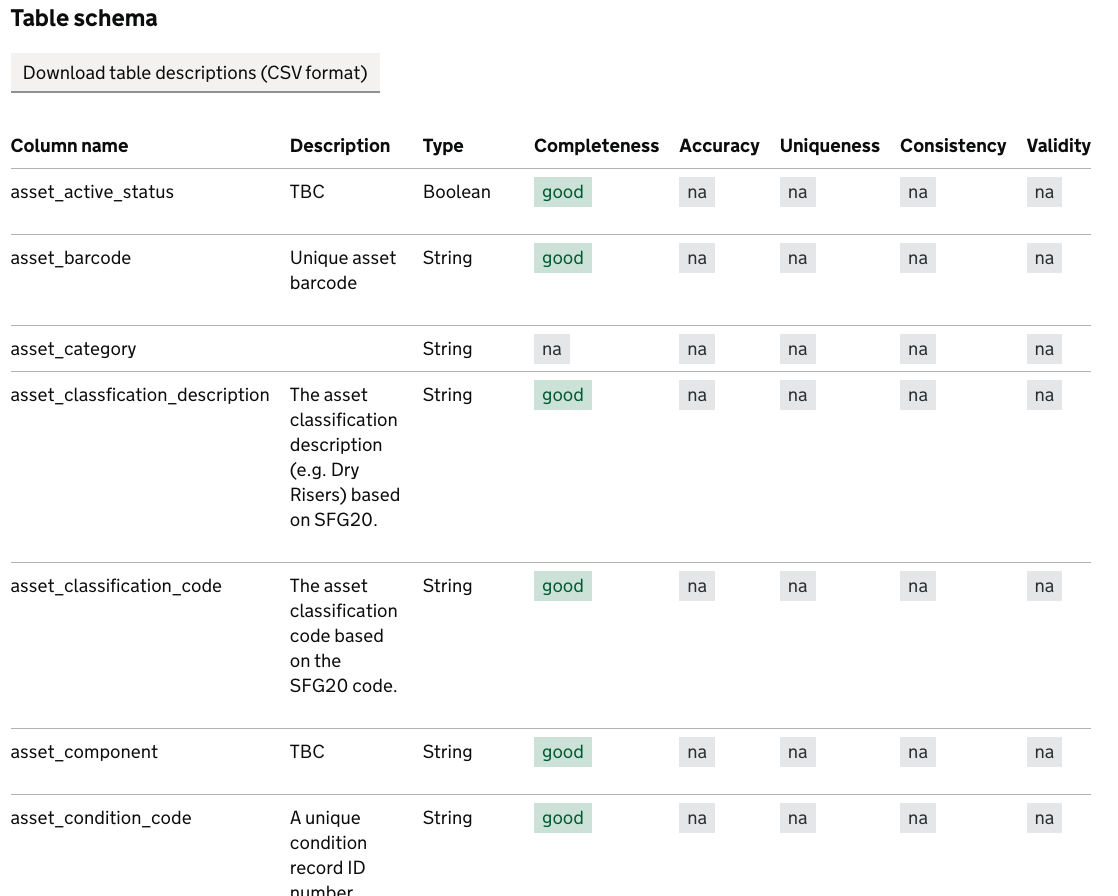
The configured tests are then applied to the appropriate columns in the all_assets table in the property database.
Some tests are given a green or amber threshold, which is used to determine whether the test passes or fails
For example, in the asset_name column, the column_completeness_green test will only pass if 95% of the columns are complete, and the column_completeness_amber test will pass if 75% of the columns are.
version: 2
models:
- name: property__all_assets
description: >
Asset record table detailing the asset classification,
count, manufacture details, etc. for an asset.
config:
tags:
- dc_display_in_catalogue
- daily
columns:
- name: asset_id
tags: ['primary_key']
data_tests:
- not_null
- unique
- column_completeness_green:
threshold: 1
- column_completeness_amber:
threshold: 1
- consistency_green:
threshold: 1
reference_source_tables:
- ref("planetfm__stg_assets")
- ref("concept__stg_assets")
- consistency_amber:
threshold: 1
reference_source_tables:
- ref("planetfm__stg_assets")
- ref("concept__stg_assets")
description: >
A unique asset ID number.
- name: asset_name
data_tests:
- column_completeness_green:
threshold: 0.95
- column_completeness_amber:
threshold: 0.75
- uniqueness_green:
threshold: 1
column_id: asset_id
- uniqueness_amber:
threshold: 1
column_id: asset_id
description: >
A name which identifies the asset (e.g. Boiler - Gas/Oil Fired) in
line with the NRM 3 classification.
- name: system_group
data_tests:
- column_completeness_green:
threshold: 0.95
- column_completeness_amber:
threshold: 0.75
description: >
The system or element group the asset relates to (e.g. Services).
- name: system_subgroup
data_tests:
- column_completeness_green:
threshold: 0.95
- column_completeness_amber:
threshold: 0.75
description: >
The system subgroup the asset relates to
(e.g. Fire and Lightning Protection).
- name: system_description
data_tests:
- column_completeness_green:
threshold: 0.95
- column_completeness_amber:
threshold: 0.75
description: >
The description of the system within the subgroup the asset relates
to (e.g. Fire Fighting Systems).
- name: asset_classification_code
data_tests:
- column_completeness_green:
threshold: 0.95
- column_completeness_amber:
threshold: 0.75
description: >
The asset classification code based on the SFG20 code.
- name: asset_classfication_description # typo
data_tests:
- column_completeness_green:
threshold: 0.95
- column_completeness_amber:
threshold: 0.75
description: >
The asset classification description (e.g. Dry Risers) based on SFG20.
- name: uniclass_code
data_tests:
- column_completeness_green:
threshold: 0.95
- column_completeness_amber:
threshold: 0.75
description: >
TBC
- name: uniclass_description
data_tests:
- column_completeness_green:
threshold: 0.95
- column_completeness_amber:
threshold: 0.75
description: >
TBC
- name: asset_component
data_tests:
- column_completeness_green:
threshold: 0.95
- column_completeness_amber:
threshold: 0.75
description: >
TBC
- name: asset_sub_component
data_tests:
- column_completeness_green:
threshold: 0.95
- column_completeness_amber:
threshold: 0.75
description: >
TBC
- name: asset_maintainer
data_tests:
- column_completeness_green:
threshold: 0.95
- column_completeness_amber:
threshold: 0.75
description: >
Identification of who has responsibility for
maintenance of this asset.
- name: asset_barcode
data_tests:
- column_completeness_green:
threshold: 0.95
- column_completeness_amber:
threshold: 0.75
description: >
Unique asset barcode
- name: asset_active_status
data_tests:
- column_completeness_green:
threshold: 0.95
- column_completeness_amber:
threshold: 0.75
description: >
TBC
- name: asset_condition_code
data_tests:
- column_completeness_green:
threshold: 0.95
- column_completeness_amber:
threshold: 0.75
description: >
A unique condition record ID number.
- name: asset_condition_name
data_tests:
- column_completeness_green:
threshold: 0.95
- column_completeness_amber:
threshold: 0.75
description: >
The current condition of the asset in accordance with
the BS 8544 definitions.
- name: asset_condition_description
data_tests:
- column_completeness_green:
threshold: 0.95
- column_completeness_amber:
threshold: 0.75
description: >
Any additional comments regarding the condition survey.
- name: asset_operational_status
data_tests:
- column_completeness_green:
threshold: 0.95
- column_completeness_amber:
threshold: 0.75
description: >
Whether or not the asset is currently in operational use.
- name: expected_life
data_tests:
- column_completeness_green:
threshold: 0.95
- column_completeness_amber:
threshold: 0.75
description: >
The length of the asset's life expectancy in years.
- name: quantity
data_tests:
- column_completeness_green:
threshold: 0.95
- column_completeness_amber:
threshold: 0.75
description: >
The count of assets at the specified location.
- name: serial_no
data_tests:
- column_completeness_green:
threshold: 0.95
- column_completeness_amber:
threshold: 0.75
description: >
The serial number fixed to the asset.
- name: make
data_tests:
- column_completeness_green:
threshold: 0.95
- column_completeness_amber:
threshold: 0.75
description: >
The make of the asset.
- name: model
data_tests:
- column_completeness_green:
threshold: 0.95
- column_completeness_amber:
threshold: 0.75
description: >
Model number of the asset.
- name: warranty_details
data_tests:
- column_completeness_green:
threshold: 0.95
- column_completeness_amber:
threshold: 0.75
description: >
The warranty expiry date for the asset.
- name: purchase_price
data_tests:
- column_completeness_green:
threshold: 0.95
- column_completeness_amber:
threshold: 0.75
description: >
Purchase price of asset in GBP.
- name: valuation_date
data_tests:
- column_completeness_green:
threshold: 0.95
- column_completeness_amber:
threshold: 0.75
description: >
TBC
- name: replacement_cost
data_tests:
- column_completeness_green:
threshold: 0.95
- column_completeness_amber:
threshold: 0.75
description: >
Cost to replace asset in GBP.
DBT Test Run and Artefacts Generation
In the case of our POC, a seperate workflow is used to run the DBT tests, generate the run_results.json and place it in the docs s3 location.
TBC - Confirm with Jacob which workflow is used.
The run_results.json file is then ingested alongside the manifest and catalogue.json files which loads the tests into Datahub,
and makes them available in the Datahub UI under the Quality tab for the given asset.
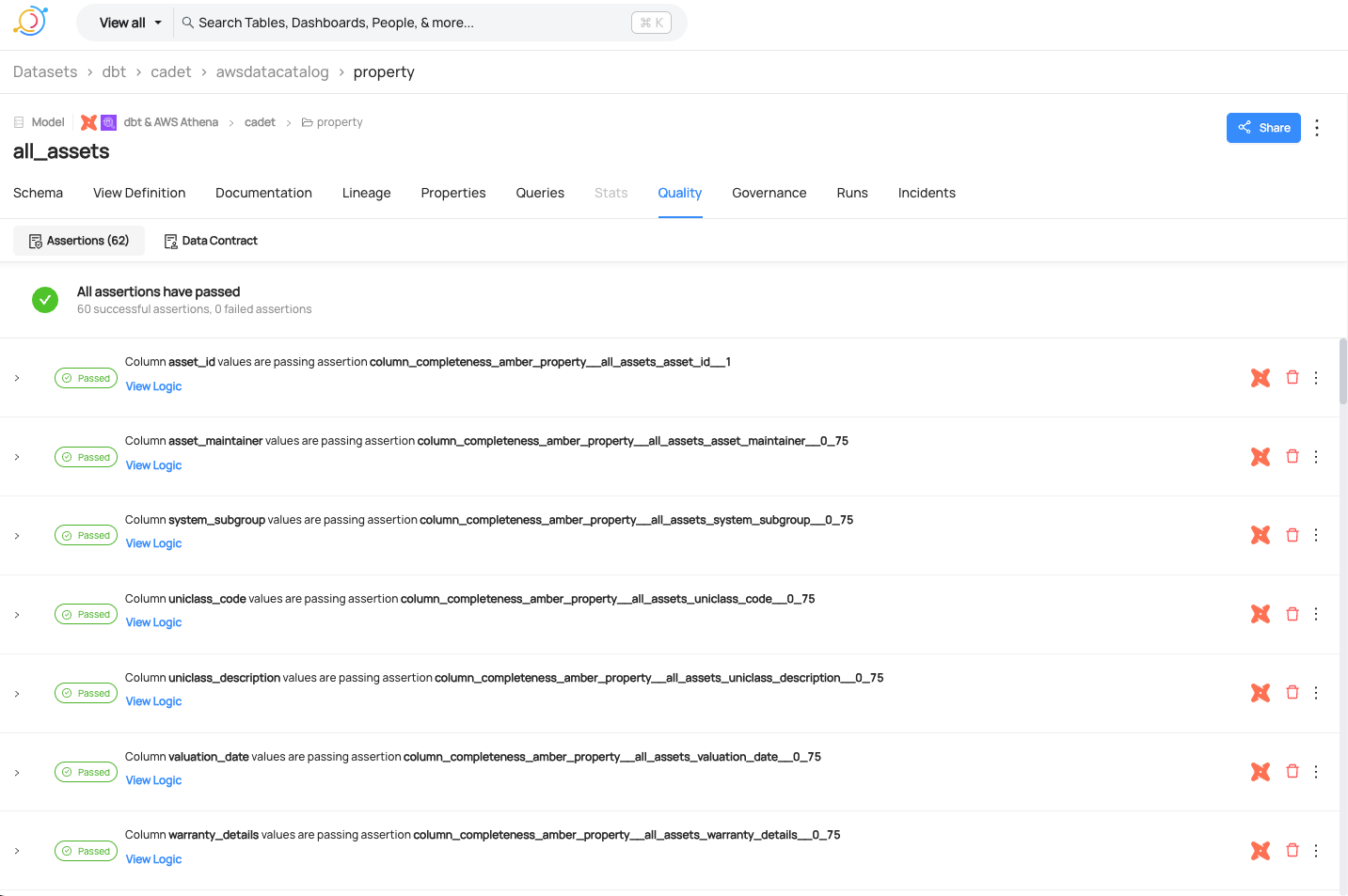
Front End Property all_assets table
The generated quality metrics are then displayed in the front end application when the given table is selected.
Useful Links
Approach for obtaining data quality metrics across wider CaDeT models
The POC is a starting point for integrating data quality metrics into Datahub, it has shown that it is possible to run DBT tests and surface the results in the catalogue.
Challenges with the existing approach
Whilst the POC has shown that it is possible to run DBT tests and surface the results in Datahub, there are some challenges with the existing approach:
- The current approach requires tests to be defined in each individual DBT model, which can be time consuming for data engineers to implement.
- Different teams are responsible for different models, which would create alot of overhead in terms of coordination and consistency.
- The data quality tests may not be implemented consistently across all models, leading to gaps in data quality coverage.
- There is no centralised way to manage and monitor data quality tests across all models, making it difficult to track progress and identify issues.
Proposed Approach
Jacob HP has proposed a potential alternative approach to generating data quality metrics, that aims to address these challenges.
This approach involves creating our own dbt project within CaDeT, containing a standard set of data quality tests that we can define and control.
We would then create a custom workflow that imports existing CaDeT DBT projects, that would run dbt test for all models in the project, and generate a single run_results.json file containing the results of all tests.
This would allow us to:
- Define a standard set of data quality tests that can be applied across all models.
- Centralise the management and monitoring of data quality tests.
- Reduce the overhead of coordinating with different teams, as the tests would be defined in a single project.
- Ensure consistency in data quality coverage across all models.